Back-propagation and Visualizing the Hidden Layers in Artificial Neural Network
This post is the continuation from our previous discussion on using Neural Network for handwriting recognition, where we will cover Neural Network in more detail in this post involving feed-forward and back-propagation. We will continue using our data for handwriting recognition, where our weights are predefined in ex4weights.mat.
Now, let us get started with the nut-and-bolts of Neural Network. Imagine we have a Neural Network model like in Figure 1. Typically, here are a few variables we use to denote our Neural Network:
- = total number of layers in the network
- = number of units (not counting bias unit) in layer
- = number of output units/classes
Therefore, in Figure 1, = 4, = 3, & = 5, = 4, and finally = 4.
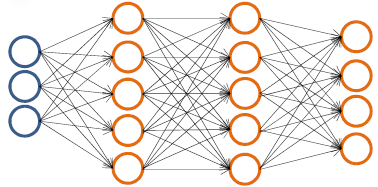 Figure 1: A Neural Network model
Figure 1: A Neural Network model
In feed-forward Neural Network, the cost function will be slightly more complicated relative to previous cost functions that we have discussed
Now let us get our hands dirty! Recall from previous post we implement the following
% adding one more columns (bias value) of 1's to the first layer
a1 = [ones(m,1) X];
% compute activation units
a2 = sigmoid(a1 * Theta1');
% again, adding one more column (bias value) to the exisiting a2
a2 = [ones(size(a2,1),1) a2];
% compute activation units
a3 = sigmoid(a2 * Theta2');
In order to implement multi-class classification, we need to first get our labels right, then we pass our labels and hypothesis to our cost function shown above, we should be able to obtain our cost value approximately 0.29.
% assign the labels accordingly
for i = 1:m
y_label(i, y(i)) = 1;
end;
% implementing the cost function
J = -1/m * sum(sum(y_label .* log(a3)+(1 - y_label) .* log(1 - a3)));
Feedforward Using Neural Network ...
Cost at parameters (loaded from ex4weights): 0.287629
Cost Function with Regularization
Recall in previous post, we discussed on how a regularized cost function can prevent the problem of over-fitting? We will do the same here, below is the cost function with regularization. (Duhhh…even more complicated. Just hang on!) We can assume that the neural network is made up of three layers - an input layer, a hidden layer and an output layer. However, it is important to take note that we should not be regularizing the terms that corresponds to the bias i.e. the first column of each matrix ( and ). We will use = 1 in this case and should be expected a cost value approximately at 0.38.
% assign the labels accordingly
for i = 1:m
y_label(i, y(i)) = 1;
end;
% implementing the cost function
J = -1/m * sum(sum(y_label .* log(a3)+(1 - y_label) .* log(1 - a3)));
% here we use sumsq() to perform sum of square
% when performing regularization, we omit the bias node
regularize = lambda/(2*m) * (sum(sumsq(Theta1(:,2:end))) + sum(sumsq(Theta2(:,2:end))));
J = J + regularize;
Checking Cost Function (w/ Regularization) ...
Cost at parameters (loaded from ex4weights): 0.383770
Back-propagation
The simplest explanation for back-propagation is to say we are minimizing our cost function, where inputs “back travel” in the network, fix some “errors”, and feed-forward again in hope to reduce the cost function. In back propagation we are going to compute for every node: = “error” of node in layer . Also, recall that our activation node in layer is . For the last layer, we can compute the vector delta values such as
To have a better sense of back-propagation, let us visualize the Neural Network model in Figure 2 and notice how is it different from feed-forward Neural Network model.
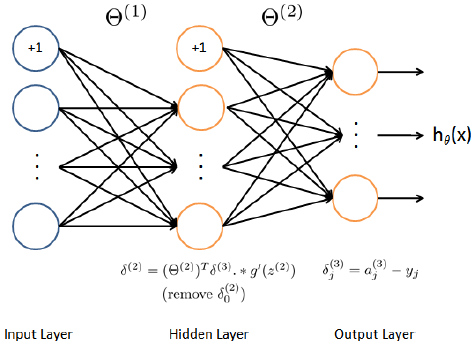 Figure 2: Back-propagation updates.
Figure 2: Back-propagation updates.
When explained using a pseudo-code approach, back-propagation will be something like below
Given training set
- Set =
0for all
For training example t = 1 to m:
- Set := ,
- Perform forward propagation to compute for ,
- Using , compute ,
- Compute using ,
- ,
- if ,
- if
MATLAB/OCTAVE implementation:
% Backword Propagation
Theta1_grad = zeros(size(Theta1));
Theta2_grad = zeros(size(Theta2));
for t = 1:m
% extracting row by row (observation) of the data
% a1 is 400+1 x 1 matrix (bias node added)
a1 = [1; X(t,:)'];
% a2 is the sigmoid result of 1x401 by 401x1 matrix product
% adding bias node to a2 (hidden layer)
a2 = [1;sigmoid(Theta1 * a1)];
a3 = sigmoid(Theta2 * a2);
% using a loop to create y_label for multiclass labels
% initialize y_label (trying another method)
y_label = zeros(1, num_labels);
y_label(y(t)) = 1;
% backpropagation starts here by computing delta
% need to add bias node too for backprop.
% but remember to exclude during accummulation
delta3 = a3 - y_label';
delta2 = Theta2' * delta3 .* [1;sigmoidGradient(Theta1 * a1)];
Theta1_grad = Theta1_grad + delta2(2:end) * a1';
Theta2_grad = Theta2_grad + delta3 * a2';
end;
% no need to regularize the bias node
Theta1_grad = (1/m) * Theta1_grad + (lambda/m) * [zeros(size(Theta1, 1), 1) Theta1(:,2:end)];
Theta2_grad = (1/m) * Theta2_grad + (lambda/m) * [zeros(size(Theta2, 1), 1) Theta2(:,2:end)];
Given the complexity of Neural Network, it is a good practice to perform gradient checking to make sure our solutions are computing correct derivative values, where we can approximate the derivative of our cost function with
where is usually set to a very small value. In this case we use = 0.0004. Do bare in mind that we only use gradient checking to ensure our gradient computations are correct, once it is correctly done, we can turn in off before running our learning algorithm. The degree to which these two vales should approximate each other will depend on the details of . But assuming = 0.0004, we will eventually find that the left and right-hand sides of the below will agree to at least 4 significant digits. At the end of this process without regularization, we obtain the relative difference of 2.33553e-011 and this give us enough confidence that our learning algorithm is working correctly. On the contrary, when regularization is involved, we obtain the relative difference of 2.25401e-011, which entails our learning algorithm is working correctly.
Checking First 10 Backpropagation (w/o regularization)...
(Left-Your Numerical Gradient, Right-Analytical Gradient)
-9.2783e-003 -9.2783e-003
8.8991e-003 8.8991e-003
-8.3601e-003 -8.3601e-003
7.6281e-003 7.6281e-003
-6.7480e-003 -6.7480e-003
-3.0498e-006 -3.0498e-006
1.4287e-005 1.4287e-00
-2.5938e-005 -2.5938e-005
3.6988e-005 3.6988e-005
-4.6876e-005 -4.6876e-005
Relative Difference: 2.33553e-011
Checking First 10 Backpropagation (with regularization)...
(Left-Your Numerical Gradient, Right-Analytical Gradient)
-9.2783e-003 -9.2783e-003
8.8991e-003 8.8991e-003
-8.3601e-003 -8.3601e-003
7.6281e-003 7.6281e-003
-6.7480e-003 -6.7480e-003
-1.6768e-002 -1.6768e-002
3.9433e-002 3.9433e-002
5.9336e-002 5.9336e-002
2.4764e-002 2.4764e-002
-3.2688e-002 -3.2688e-002
Relative Difference: 2.25401e-011
Results
Once again to highlight the effects of , we will use three different values of 0, 0.1, 1 and 10 respectively to compute the cost function and training accuracy. Do that note that results may vary due to random initialization, if we want to ensure we get the same result in every run, we may set the seed. We will move along without a fixed seed in this post.
| Cost Value at Iteration | =0 | =0.1 | =1 | =10 |
|---|---|---|---|---|
| 20 | 8.639456e-001 | 7.471765e-001 | 7.986812e-001 | 1.349767e+000 |
| 40 | 4.598028e-001 | 4.481630e-001 | 4.698736e-001 | 1.086830e+000 |
| 60 | 2.918327e-001 | 2.967013e-001 | 3.986810e-001 | 1.049596e+000 |
| 80 | 2.120243e-001 | 1.726550e-001 | 3.626124e-001 | 1.030520e+000 |
| 100 | 1.249149e-001 | 1.373722e-001 | 3.550107e-001 | 1.016049e+000 |
| Training Accuracy | |
|---|---|
| 0 | 99.12 |
| 0.1 | 99.36 |
| 1 | 98.16 |
| 10 | 93.48 |
From the table above, we can observe that smaller (even no ) yields best results among the tested , however it is prone to the problem of over-fitting. But when is big, the problem of under-fitting occurs. To enjoy the best of both worlds, let just take just somewhere in the middle, which is = 1.
Visualizing the hidden layer
Up to this point, we have discussed many of the underlying mathematical theory that surrounds Neural Network. Now, for something more interesting, let us visualize the effects of towards the hidden layer of our Neural Network in Figure 3.
 Figure 3: Visualizing hidden layers using different
Figure 3: Visualizing hidden layers using different
As we can observe, as the value of increases from small to big, the images get more blur and less define, which also illustrate the idea of regularization. Too little of regularization results in over-fitting, and too much of regularization results in under-fitting.
To wrap it up, the following table compares the strengths and weaknesses of Artificial Neural Network.
| Strengths | Weaknesses |
|---|---|
| Can be adapted to classification or numeric prediction problems | Extremely computationally intensive and slow to train,particularly if the network topology is complex |
| Capable of modeling more complex patterns than nearly any algorithm | Very prone to overfitting training data |
| Makes few assumptions about the data’s underlying relationships | Results in a complex black box model that is difficult, if not impossible, to interpret |
That is all for now. Do stop by here again next year for more updated!
Wishing you all a Happy New Year!!!